
日前,GB 18030-2022的1号修改单发布了第二次征求意见稿,
从它编制说明的附件中的处理意见来看,很明显起草组不顾国际组织的建议,铁了心要在第十平面发布“公安人口信息专用字库补充汉字”,这在修改单初次征求意见时就饱受诟病。他们并坚持所谓“以国家标准引领国际标准的发展理念”,预计仍会在8月1号实施。能做的只是快去提提意见。
该第二次征求意见稿的第十平面由上一版的897字减少到614字,并且改以部首笔画排序,这点来说还是无可挑剔的,如果没有在编制说明的附件中把614字误作615字的话。
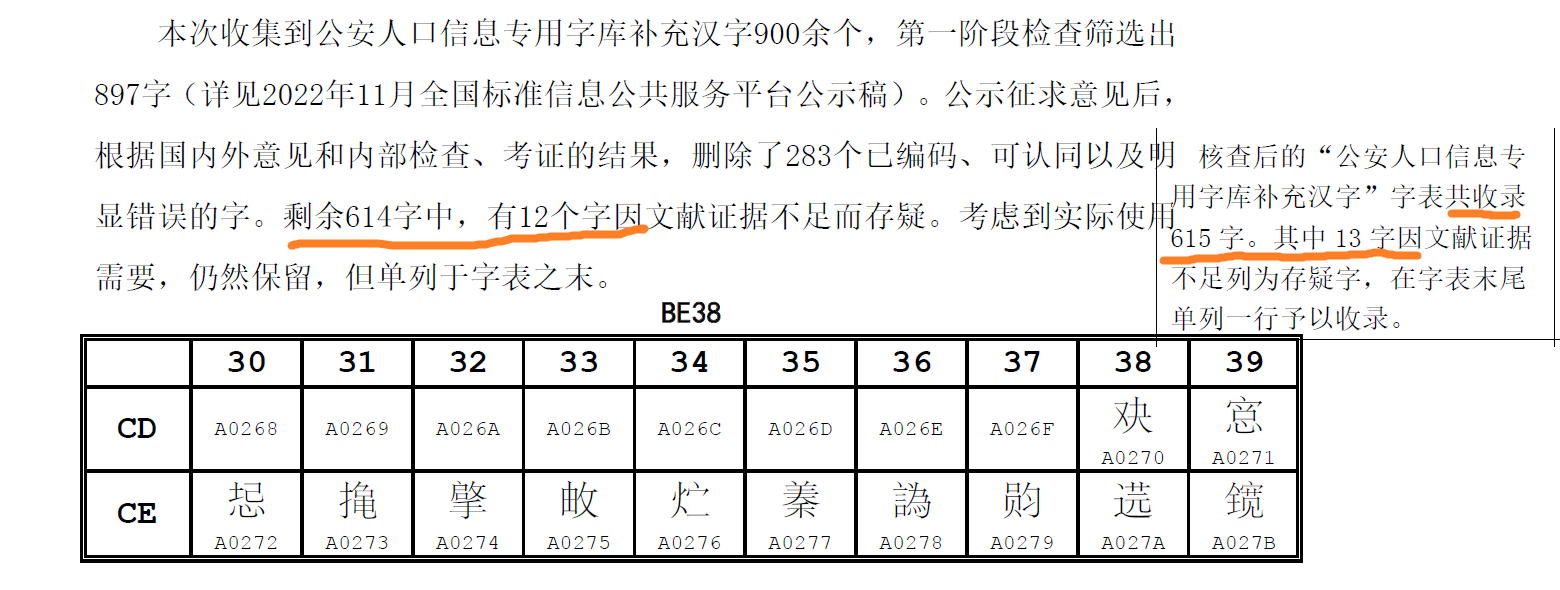
根据编制说明,删除的字是“已编码、可认同以及明显错误的字”,而剩余614字中有12字“因文献证据不足而存疑”,被孤零零地丢在“公安人口信息专用字库补充汉字”的最末,尽管我们一眼就可以在这里扫到U内的“𫭻”字。
那么第二次征求意见稿中应该没有可认同重复字了吧。打开看一下,一眼就可以看到:
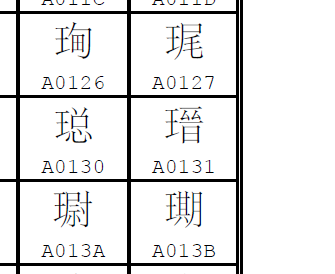 “我去,瑨!”
“我去,瑨!”
可能是起草组对“认同”有着独到的理解,也可能此rèntóng非彼unification。Unicode已经收了同形重复的两个⿰王晋了这是还嫌不够多是吧。“瑨”字G源来自G3(三辅,二辅的对应繁体版本),没人见过,翻开二辅还是能看到对应位置的字从晋,根据其他国标也可知三辅中字形应一样从晋,也就是说当时在G源的立场来看这个字就是从晋,不存在从晉的写法,在当时的规则下从晋的自然和其他源都从晉的认同了。如今“瑨”作为已稳定的《通规》三级字当然需要规范字形维持在基本区。而在垃圾场扩B的“𤨁”是来自T源的一个同形俗字,按当时处理垃圾一样编码汉字的做法新开了字头,要是放现在也就是一个IVD的事儿。

如果我没理解错的话,根据统一码技术委员会和美国国际信息技术标准委员会给修改单的建议,他们觉得对于18030第十平面拟添加的这种分离字可以给国标维护一个新IVD。要是当时G就有分立从晋从晉两个字头的编码的话,根据当时的规则肯定就在基本区分成两个字头了,不会有现在这种事,谁让你现在才想起来编呢?
由处理意见和国标全文来看,国标都肯定不想接受使用IVD的方案,这一点也可能是技术原因。真有人搭理你“以国家标准引领国际标准的发展理念”吗?就是走急用汉字也轮不到放第十平面去吧?国标正式发布后这里面除去重复字必然会走正常入U流程,到时再来一遍当年GBK PUA的惨案,不如说像GBK用PUA还好一点,18030直接把待定义的平面给hack了,玩儿呢?国标第十平面直接“应与标准中其他部分一样作为正式码位看待”了!而且这是个强制国家标准,等修改单缓冲期过了(预计2024年9月)连Windows都会能把这一堆待定义Unicode字符显示成汉字!然后再过几年这堆字又正常进U了所有人都在用PUA都不如的非法码位‼不记得什么大小䶮折腾了多少人了吗⁈18030是个编码方案,这和《通规》加U外字的性质完全不同。
对新平面迟到的吐槽到此结束,我是能理解18030这种做法的初衷的,把RKXX干掉挺好的,就是hack新平面真的没品。而且好像有一些二简、八辅、不规范类推字,能推动入U也挺好。其中还有一些已经提交过但被U掉的,如“⿰石㐫”“⿱艹⿰立匀”,坚持要单独编码这些字也算是一种,呃,我不好说是什么,编制说明说是“国家标准先行,首先满足自身需要”。
来看一看这个第二次征求意见稿删完二百多个字还剩几个有问题的。删除有不合理的随缘吧,这种赛博垃圾还是越少越好(没有说字本身不好的意思)。不过也许上一版中的A0021(⿰石戋)删掉后修改单可以加一句把2548E的字形修改为⿰石戋的……现在写的是⿰石㦮……
上面的“瑨”这种已编码字的垃圾远不止这一个。这是什么,看一下?这不是𦲞吗?
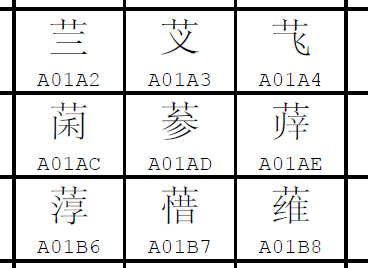
“𦲞”这个字是没有G列的,而且很容易注意到T列从叁,其余从参。
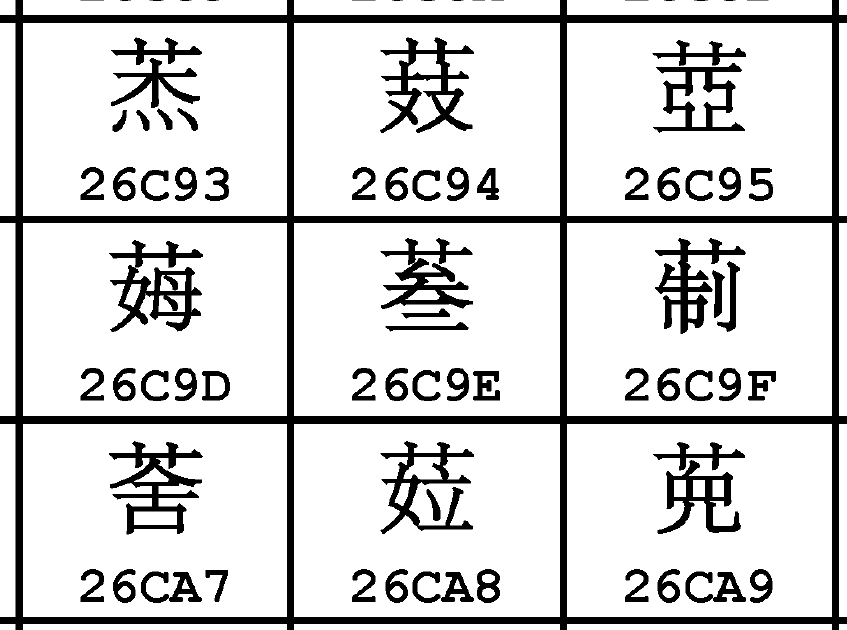
众所周知GB18030的码表是随缘选择字形的,你可以选择叫它“真想G源”[1],但它很多字完全不G。我们翻开国标原文找一找这个字。
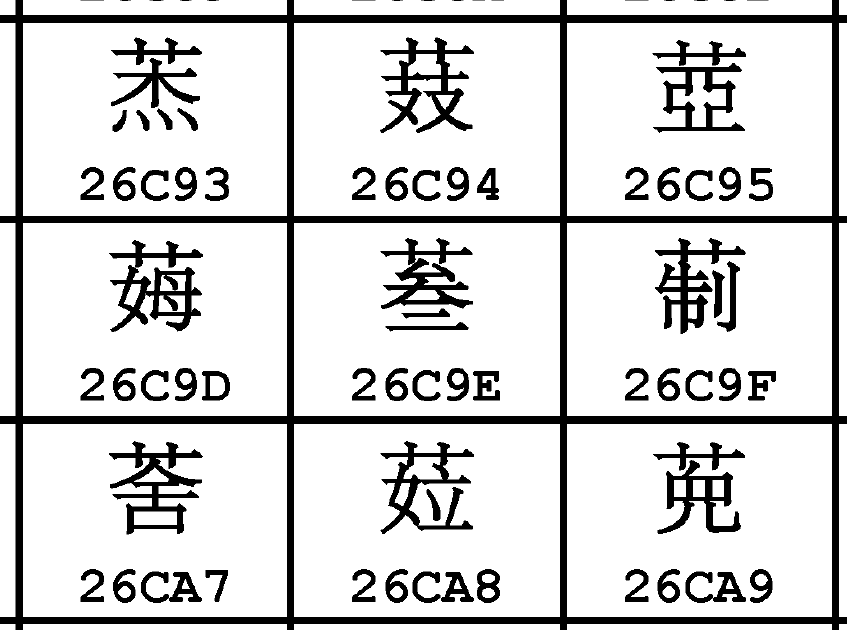
从叁是吧?𦲞没字可认同了是吧?活该!
你一个编码标准本来也是个混标,管不着字形具体怎么写,你也用不上从叁的字形,正趁着出修改单了,你就把你那扩B字形改成你用的呗。而且你都有证据了,下次把你那𦲞也横扩一下不就完了。
这里有由此想到的一个问题,只支持到第二级别就可以的设备支持了部分第三级别的汉字,但写法和18030的码表不一样合不合规?说的就是fallback着思源黑的广大安卓机。
RKXX继承下来的一些错讹字,这次修改后还在的,国标明摆着因为系统内有实际用例不会删了。不管是什么字,总之再来看一遍,还有没有该认同(unify)你没认同(rèntóng)的吧。
我能想到的理论上这种字根据是否用到IVD大致分为两类,“瑨”和“𦲞”分别是两类的代表。第二类完全可以且应该从这份修改单中删掉。
- 在U内已有G列,而国标想要新增与G列不同的字形,需要通过IVD,国标不认可,例如“瑨”。或者在U内尚无G列,但国标可以通过选取已有IVD来得到需要新增的字形,国标同样不认可。
- 在U内尚无G列,国标可以通过在正式码位选取合适列的字形来得到需要新增的字形,从而不需要新增码位,例如“𦲞”。或者在U内尚无G列,国标可以通过横扩来得到需要新增的字形。
部分字列举如下。这里不赘述已经被U掉的字。
| 第二次征求意见稿编码 | 同形字 | 同形源 | 有无G列 |
|---|---|---|---|
| A008A | 𭹊 | UK(差避让) | 无 |
| A0131 | 瑨 | H、T、J、K | 有 |
| A01A3 | 芆 | T | 有 |
| A01AD | 𦲞 | V、UK | 无 |
| A0272 | 𫭻 | V | 无 |
| A0278 | 譌 | H | 有 |
𭹊𦲞𫭻这仨字儿不扬了你睡得着吗起草组?
如果你也觉得这个修改单的第二次征求意见稿有不合理的地方,不如组团儿去提提意见?
注释
- ↑与“假想G源”相对,后者直译自日文「仮想Gソース」,指为汉字构想符合G源一般书写习惯的字形。